Pygame Merge Red Green and Blue Pixel Arrays
How RGB and Grayscale Images Are Represented in NumPy Arrays
Let's start with image basics
Today, you're going to learn some of the most important and fundamental topics in machine learning and deep learning. I guarantee that today's content will deliver some of the foundational concepts that are key to start learning deep learning — a subset of machine learning.
First, we'll begin describing image basics such as pixels, pixel values, image properties and the difference between RGB and grayscale images. Then we'll talk about how these images are represented in NumPy arrays.
As a bonus section, we'll explore the MNIST digits dataset (see citation at the bottom) that contains thousands of grayscale images of handwritten digits. This will help you to further clarify the things you learned in NumPy representation of images.
Therefore, today's content will be dived into two main sections:
- Basics of images — key components and representations
- A closer look at the MNIST dataset (Optional)
We begin with the basics of images.
Basics of images
Pixels
An image is made of tiny, square-like elements called pixels. Even a small image can contain millions of such pixels of different colors.
Image properties
Every image has three main properties:
- Size — This is the height and width of an image. It can be represented in centimeters, inches or even in pixels.
- Color space — Examples are RGB and HSV color spaces.
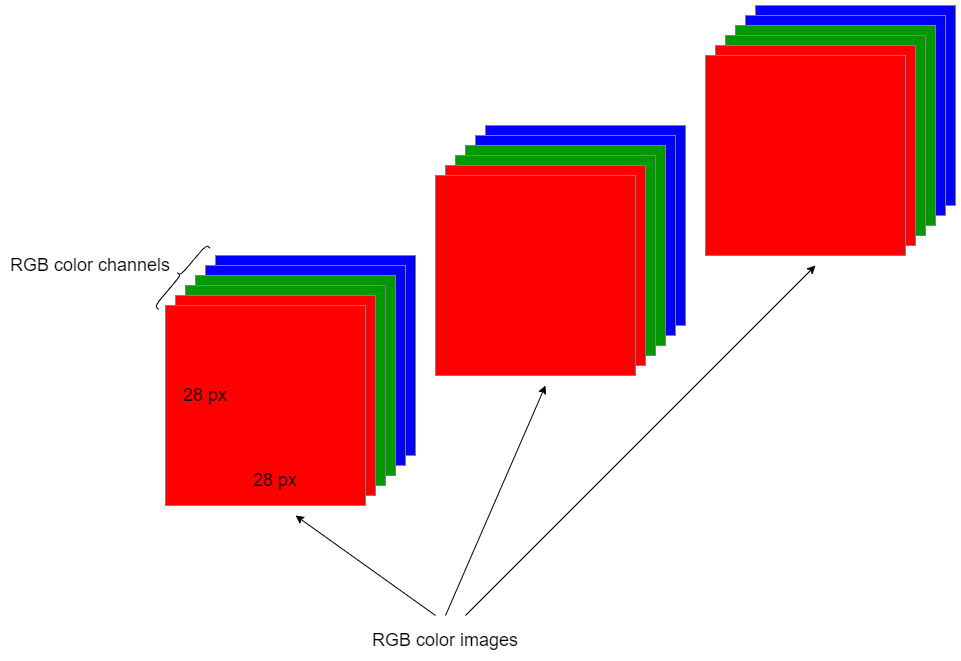
- Channel — This is an attribute of the color space. For example, RGB color space has three types of colors or attributes known as R ed, G reen and B lue (hence the name RGB).
RGB images vs grayscale images
It is important to distinguish between RGB images and grayscale images. An RGB image has three color channels: Red channel, Green channel and Blue channel. However, a grayscale image has just one channel.
Pixel values
The colors of an image are denoted by its pixel values. A pixel can have only one color but can be merged to create multiple colors.
In a grayscale image where there is only one channel, a pixel value has just a single number ranging from 0 to 255 (both inclusive). The pixel value 0 represents black and the pixel value 255 represents white. A pixel value in a grayscale image can be represented as follows:
[40] Since the value 40 is close to 0 rather than 255, the color of the pixel is also close to black!
In an RGB image where there are three color channels, a pixel value has three numbers, each ranging from 0 to 255 (both inclusive). For example, the number 0 of a pixel in the red channel means that there is no red color in the pixel while the number 255 means that there is 100% red color in the pixel. This interpretation is also valid for pixels in the other two channels. A pixel value in an RGB image can be represented as follows:
[255, 255, 0] This pixel value represents the yellow color. Look at the following picture.

The yellow color is made from green and red colors. No blue color is involved. That's why the pixel value [255, 255, 0] represents a yellow color pixel — Red 100% (255), Green 100% (255), and no Blue (0)!
Image representation in deep learning
In machine learning and deep learning, images are represented as NumPy arrays. In the context of deep learning, those NumPy arrays are technically called tensors (Learn to create Tensors like NumPy arrays).
Most of you may get confused when representing images in NumPy arrays because multiple dimensions are involved. Basically, the number of dimensions is decided by the following factors.
- Image size — Two dimensions are always needed to represent the height and width of the image.
- Color channel
- Number of images
Grayscale image representation as NumPy arrays
A single grayscale image can be represented using a two-dimensional (2D) NumPy array or a tensor. Since there is only one channel in a grayscale image, we don't need an extra dimension to represent the color channel. The two dimensions represent the height and width of the image.
A batch of 3 grayscale images can be represented using a three-dimensional (3D) NumPy array or a tensor. Here, we need an extra dimension to represent the number of images.

The shape of the above batch of 3 grayscale images can be represented as:

RGB image representation as NumPy arrays
A single RGB image can be represented using a three-dimensional (3D) NumPy array or a tensor. Since there are three color channels in the RGB image, we need an extra dimension for the color channel.
A batch of 3 RGB images can be represented using a four-dimensional (4D) NumPy array or a tensor. Here, we need an extra dimension to represent the number of images.
The shape of the above batch of 3 RGB images can be represented in two different ways:
- Channels-last: This places the color channel axis at the end. This is standard in TensorFlow (Keras) and OpenCV.
- Channels-first: This places the color channel axis after the samples axis.

Top takeaway: The channels-last notation is the standard notation for representing RGB images as NumPy arrays.
Enough theory for image basics and its NumPy representation. Let's begin to explore the MNIST digits dataset.
A closer look at the MNIST dataset (Optional)
The MNIST digits dataset (see citation at the bottom), constructed by the NIST (National Institute of Standards and Technology), is a classic dataset for learning deep learning and also general machine learning. It has been overused by the machine learning and deep learning community. However, it is still worth exploring and using this dataset, especially, if you're going to touch deep learning for the very first time.
The MNIST dataset contains 70,000 grayscale images of handwritten digits under 10 categories (0 to 9). We will use two popular APIs for loading the dataset: Keras API and Scikit-learn API. Both provide utility functions to load the MNIST dataset easily. We will also discuss the differences between the two APIs for the MNIST dataset.
Loading the MNIST dataset using the Keras API
from tensorflow.keras.datasets import mnist (train_images, train_labels), (test_images, test_labels) = mnist.load_data()
Getting the shape of the data
print("Train images shape:", train_images.shape)
print("Train labels shape:", train_labels.shape)
print("Test images shape: ", test_images.shape)
print("Test labels shape: ", test_labels.shape) 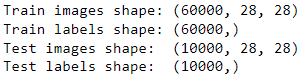
The batches of train and test images are three-dimensional. This is because the MNIST dataset contains grayscale images, not RGB images. The (60000, 28, 28) means the train image set contains 60,000 images of 28 x 28 px. In other words, it is an array containing 60,000 matrices of 28 x 28 integer values.
The train and test labels are one-dimensional. They contain the correspondent labels for 10 categories (0 to 9).
import numpy as np np.unique(test_labels)
#OR
np.unique(train_labels)
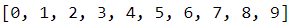
Getting the array type
print("Train images type:", type(train_images))
print("Train labels type:", type(train_labels))
print("Test images type: ", type(test_images))
print("Test labels type: ", type(test_labels)) 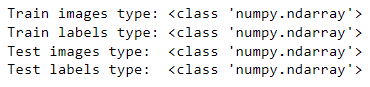
All are NumPy arrays.
Getting the data type
print("Train images data type:", train_images.dtype)
print("Train labels data type:", train_labels.dtype)
print("Test images data type: ", test_images.dtype)
print("Test labels data type: ", test_labels.dtype) 
The data type of pixel values is "uint8" which denotes 8-bit integers.
Getting a single image from the train image set
A single image from the train set can be accessed by using the following notation:
train_images[i] The index is 0 based. To get the 10th image, we should use i=9.
train_images[9] 
train_images[9].shape This is a 28 x 28 matrix of a grayscale image.
Visualizing a single image
We'll visualize the 10th image of the training dataset.
import matplotlib.pyplot as plt tenth_digit = train_images[9]
plt.imshow(tenth_digit, cmap="binary")
plt.axis("off")
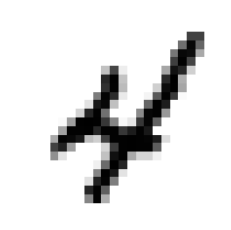
The 10th image of the training set represents the number 4. Let's see whether it is correct by looking at its corresponding label.
train_labels[9] This also returns 4. So, the image is correspondent to its label.
Loading the MNIST dataset using the Scikit-learn API
from sklearn.datasets import fetch_openml mnist = fetch_openml('mnist_784', version=1) X, y = mnist['data'], mnist['target']
Getting the shape of the data
print("X shape:", X.shape)
print("y shape:", y.shape) 
The pixel values of a single image are arranged in a one-dimensional vector of size 784 which is equal to 28 x 28. This means we can still reshape the vector to get the required format for the image as in the Keras API.
Getting the array type
print("X type:", type(X))
print("y type:", type(y)) 
Getting the data type
print("X data type:", X.dtypes) 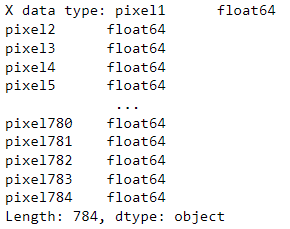
print("y data type:", y.dtypes) 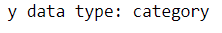
Differences between the two APIs for the MNIST dataset
- Train and test sets: In Kears, the MNIST dataset can be loaded with train and test sets. But in Scikit-learn, we need to create the train and test parts manually.
- Shape: In Keras, a single MNIST digit is represented by a two-dimensional NumPy array of size 28 x 28. In Scikit-learn, a single MNIST digit is represented by a one-dimensional NumPy array of size 784. We need to explicitly reshape the array into a 28 x 28 array.
- Array type: In Kears, images and labels are repeated by NumPy arrays. In Scikit-learn, images are repeated by a Pandas DataFrame while labels are represented by a Pandas series.
- Data type: In Kears, the data type of pixel values and labels is "uint8" which denotes 8-bit integers. In Scikit-learn, the data type of pixel values are "float64" and the data type of labels are "category" that should be converted into "uint8" before using in the algorithms as follows.
y = y.astype(np.uint8) Top takeaway: If you're using the MNIST dataset for deep learning purposes, I recommend you load the data using the Keras API.
Read next (Highly recommended)
Learn to create Tensors like NumPy arrays.
Learn NumPy basics and array creation.
Slice NumPy arrays like a pro.
Read next (Optional)
Compress images using PCA!
This is the end of today's post.
Please let me know if you've any feedback.
Meanwhile, you can sign up for a membership to get full access to every story I write and I will receive a portion of your membership fee.
Thank you so much for your continuous support! See you in the next story. Happy learning to everyone!
MNIST digits dataset citation:
Deng, L., 2012. The mnist database of handwritten digit images for machine learning research. IEEE Signal Processing Magazine, 29(6), pp. 141–142.
MNIST digits dataset source:
http://yann.lecun.com/exdb/mnist/
MNIST digits dataset license:
Yann LeCun (Courant Institute, NYU) and Corinna Cortes (Google Labs, New York) hold the copyright of the MNIST dataset that is made available under the terms of the Creative Commons Attribution-Share Alike 3.0 license.
Rukshan Pramoditha
2021–12–04
Source: https://towardsdatascience.com/exploring-the-mnist-digits-dataset-7ff62631766a
0 Response to "Pygame Merge Red Green and Blue Pixel Arrays"
Post a Comment